
確率的生成モデルに基づく音楽の類似度とありがち度の推定
中野 倫靖, 吉井 和佳*1, 後藤 真孝
産業技術総合研究所, *1京都大学
研究背景
音楽がデジタル化されアクセス可能な楽曲が単調増加
- 人々が音楽の「何が似ているのか」「どれぐらいありふれているのか」を知ろうと思った時に容易に知るための手段の実現
- 過去の楽曲と共存共栄し、敬意を払う文化を築くことへの貢献
例)論文のように引用され再利用されたら喜びを感じられる音楽文化
カバー曲の制作やニコニコ動画でのN 次創作においては引用が一般的
新規楽曲を発表する際に他の楽曲への引用を記述することは稀
音楽要素の確率的生成モデル
歌声と伴奏を含む音楽音響信号の音楽要素の生成モデル
- 各音楽要素(音響特徴量や和音進行)がどういう形で出現しやすいかその確率(生成確率)を計算できるモデル
- 生成確率によって「楽曲間の類似度」や「楽曲のありがち度」を推定する
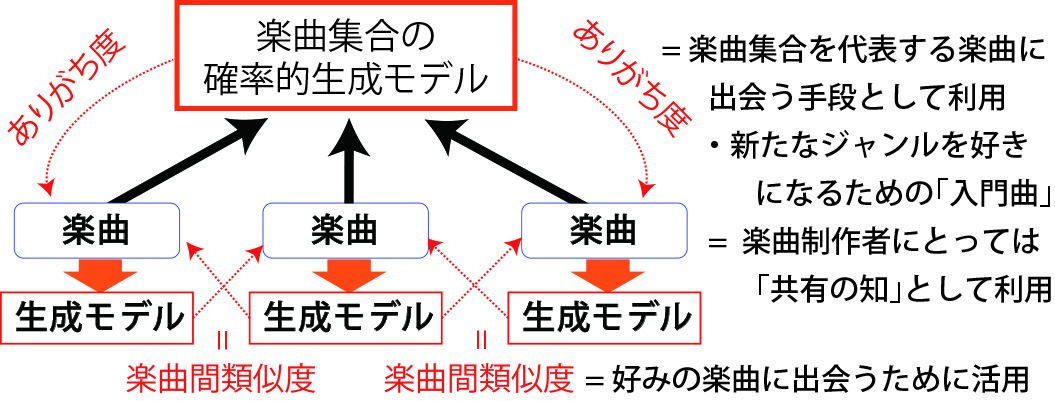
※現時点では、音楽要素を生成したり楽曲を作ったりすることはできない
(将来的には生成できるよう発展できる可能性がある)
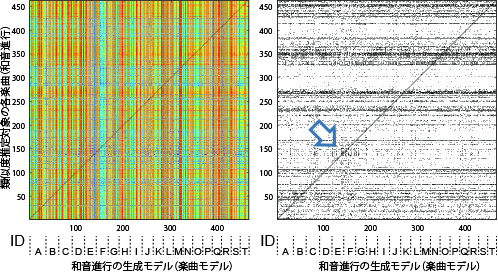
実験A: 類似度
楽曲毎の生成モデルをポピュラー音楽3278曲で学習
- オリコン上位20 位以内(2000-2008)
- 楽曲数が多い上位20アーティストの楽曲463曲

【歌声】
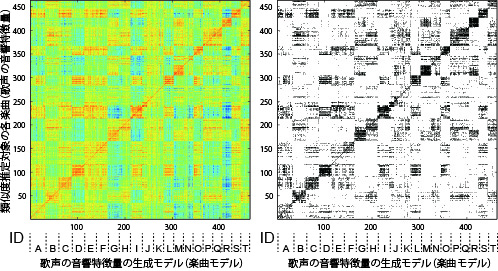
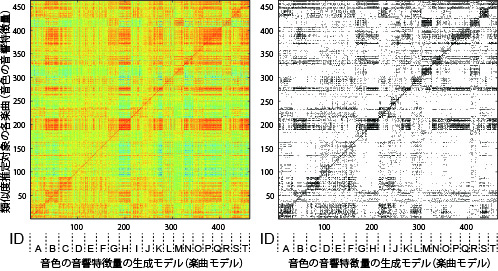
【音色】
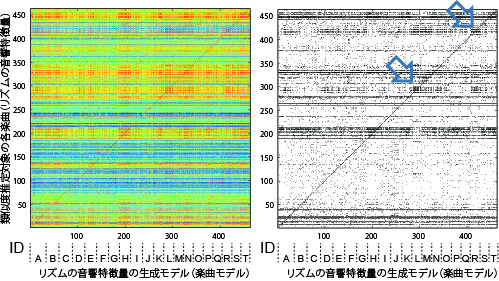
【リズム】
【和音進行】
作品の発表時に盗作疑惑を招く事例が増えてしまう懸念
- 類似度に関する人間の能力の限界に起因
楽曲全てを聞いて全体を俯瞰した適切な判断を行うことは不可能 - あらゆる楽曲は既存曲の影響を受けている
「無自覚に」「何らかの意味で」「部分的に」類似してしまうのは自然 - 自分の作品が何かに似ていると糾弾されるリスクが高いと安心して楽曲の制作や発表をしにくい社会になりかねない
過去の楽曲に敬意を払う文化、感動体験重視型の音楽文化へ
- 「他に類似していないか」という新規性だけを追求するのではなく過去の楽曲と共存共栄し、人々を感動させる魅力や完成度の高さ等を重視
分析対象と生成モデル
ボーカルの歌声
- 線形予測メルケプストラム係数 (LPMCC)、ΔF0
- [生成モデル] 潜在的ディリクレ配分法(Latent Dirichlet Allocation: LDA)
楽曲中の音色
- メル周波数ケプストラム係数 (MFCC), ΔMFCC, Δパワー
- [生成モデル] 潜在的ディリクレ配分法(Latent Dirichlet Allocation: LDA)
リズム
- Fluctuation Pattern (FP)
- [生成モデル] 潜在的ディリクレ配分法(Latent Dirichlet Allocation: LDA)
和音進行
- 8 種類の代表的な和音とその12 種類の根音(+和音がない区間)
= major, major 6th, major 7th, dominant 7th, minor, minor 7th, diminished, augmented
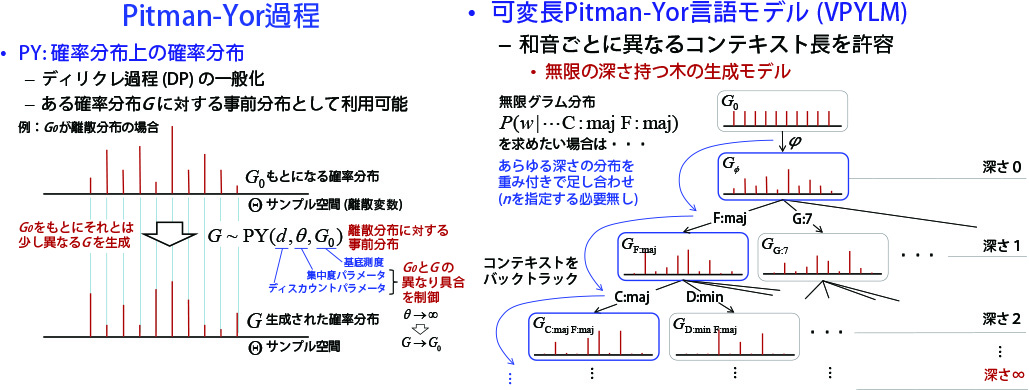
- [生成モデル] 可変長Pitman-Yor 言語モデル(VPYLM)
実験B: ありがち度
RWC研究用音楽データベース(ポピュラー音楽)100 曲を推定
- 実験Aで学習したポピュラー音楽3278曲の生成モデル(楽曲集合のモデル)
